浏览器工作原理之渲染引擎
背景
之前参加极客时间的训练营,学习到了浏览器工作原理,一直心心念念的想要记录一下,今天来填坑了属于是。
话不多说,我们先来看一张图:
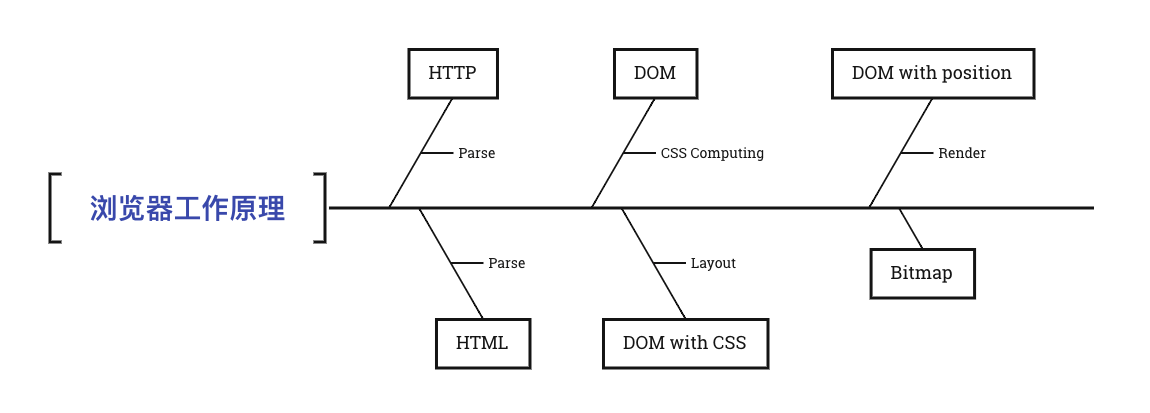
具体流程,主要分为以下几个部分:
HTTP Parse
在浏览器中访问一个 URL,浏览器作为客户端发起 HTTP 请求,经过 DNS 解析、找到并访问服务器的 IP 地址,服务器响应请求,浏览器解析 HTTP 响应。
浏览器在其中做的事情:
- 创建
HTTP请求报文 - 解析
HTTP响应报文
HTTP 请求报文
<!-- Request Line-->
POST / HTTP/1.1
<!-- Headers -->
Host: localhost:8088
Content-Type: application/x-www-form-urlencoded
Content-Length: 21
<!-- Body -->
field1=aaa&code=x%3D1
上面是一个 POST 请求的 HTTP 示例代码,主要由三部分组成:
- Request Line
- Method
- Path(default: /)
- HTTP/HTTP Version
- Headers
- Host:Port
- Other
- Body
Method 、Path Headers 都是 HTTP 协议要求的,Headers 中的 Host 是 IP 协议要求,Port 是 TCP 协议要求的。
HTTP 响应报文
<!-- Status Line -->
HTTP/1.1 200 OK
<!-- Headers -->
Content-Type: text/html
Date: Thu, 24 Dec 2020 07:27:19 GMT
Connection: keep-alive
Transfer-Encoding: chunked
<!-- Body -->
d\r\n
Hello World!\r\n
0\r\n
\r\n
上面是一个 HTTP 响应的示例代码,主要由三部分组成:
- Status Line
- HTTP/HTTP Version
- HTTP Status Code
- HTTP Status Text
- Headers
- Body
- Chunk Length(16 进制数)
- Body Text
- 0
- Trailer(可能为空)
Transfer-Encoding 标头指定了编码时使用的安全传输的形式,在 Node.js 中默认是 chunked,表示分块传输,body 中的数据结构会受其影响
HTML Parse
将 HTML 文本解析并生成一颗 DOM 树结构的数据。
<html lang="en">
<head>
<title>Document</title>
<style>
body div #title {
font-size: 24px;
font-weight: 500;
color: red;
}
body div p {
color: green;
}
</style>
</head>
<body>
<div id="app">
<p id="title">Helll World!</p>
<p>--by Lsnsh</p>
</div>
</body>
</html>
词法分析
function parseHTML(html) {
// 初始状态
let state = data;
for (let c of html) {
state = state(c);
}
// 最终状态
state = state(EOF);
}
获取到 HTML 文本后,通过有限状态机(FSM)进行 HTML 词法分析(将字符序列转换为标记序列的过程),期间会经过「标记化/分词」(tokenization)最后得到一系列的「标记/词」(token)。
解析标签相关的状态:
- data
- tagOpen
- endTagOpen
- tagName
- beforeAttributeName
- selfClosingStartTag
- EOF
解析属性相关的状态:
- attributeName
- afterAttributeName
- beforeAttributeValue
- doubleQuotesAttributeValue
- singleQuotesAttributeValue
- afterQuotesAttributeValue
- noQuotesAttributeValue
token 的类型:
- startTag
- endTag
- text
- EOF
语法分析
const token: {
type: string; // 标签类型(startTag、endTag、text、EOF)
tagName: string; // 标签名
content: string; // 标签内容
isSelfClosing: boolean; // 标记是否为自封闭标签
};
词法分析之后,进入 HTML 的语法分析阶段,基于准备好的 token 构建一颗 DOM 树:
- 从标签构建
DOM树的基本技巧是使用栈 - 遇到开始标签时创建元素并入栈,遇到结束标签时出栈
- 自封闭节点可视为入栈后立即出栈
- 任何元素的父元素都是它入栈前的栈顶位置的元素
简单的语法分析,可以使用一个栈来处理,实际浏览器中要处理各种特殊情况(eg: 标签未封闭时自动封闭等处理),完整构建一棵树,可以查看 HTML 规范 - Tree construction
CSS Computing
<style>
body div #title {
font-size: 24px;
font-weight: 500;
color: red;
}
body div p {
color: green;
}
</style>
CSS Computing - CSS 计算,就是把 CSS 规则中所包含的 CSS 属性应用到匹配这些选择器的元素上去,最后生成一颗带 CSS 属性的 DOM 树。
需要经过以下几步:
- 收集
CSS规则 - 计算选择器与元素匹配
- 生成
computed属性 - 样式优先级(
specificity)的计算逻辑- 四元组
- 后来者优先级更高
DOM Layout
经过成 HTML 解析 和 CSS 计算 最终得到一颗带样式的 DOM 树。在此基础上通过排版的计算得到一颗带位置的 DOM 树。
DOM Render
绘制单个元素:

最后渲染绘制出 DOM 树。

- 实际浏览器中,文字绘制是难点,需要依赖字体库,我们这里忽略
- 实际浏览器中,还会对一些图层做
compositing,我们这里也忽略了
总结
- 开始一个
URL到一段HTML代码 - 从这段
HTML代码构建起一颗DOM树 - 又给这颗只有节点基本信息的 DOM 树加上了 CSS 属性
- 结合这些 CSS 属性经过排版得到 DOM 树每个节点的位置
- 最后将这颗 DOM 树,渲染出了一帧(图片)
最后我们简单了解一下浏览器的重要组成部分——浏览器内核,内核主要由两部分组成:
- 渲染引擎
- 负责对网页中的内容进行解析、渲染和绘制
JavaScript引擎- 负责提供
JavaScript的运行环境
- 负责提供
回顾开篇看到的那张图,细心的你会疑惑,只提到 HTML 和 CSS,没提到 JavaScript(script 标签、DOM 对象、浏览器事件等)。
其实由于内容复杂和时间关系,前面提到的很多部分其实也没能详细介绍。而 JavaScript 又是又是属于浏览器中的另一大部分,所以说是讲「浏览器工作原理」其实叫「浏览器工作原理之渲染引擎」可能会更贴切一些。